:quality(85)&w=1536&q=85)
:quality(85)&w=1536&q=85)
:quality(85)&w=1536&q=85)
Very few conversations about enterprise AI go into detail about how AI agents should actually make decisions for back-office processes like reconciling invoices, closing your books, or matching supplier documents across four different systems. Even fewer off-the-shelf AI platforms have the capability to use different reasoning approaches for different situations.
That matters because different back-office problems require fundamentally different reasoning strategies. An agent that monitors your ERP and HCM applications for anomalies needs to think differently than one that matches an invoice to a purchase order, a goods receipt, and a contract. Getting this wrong is why so many enterprise AI deployments underperform.
Vendors apply one reasoning approach to every problem, ship a generic copilot, and wonder why 95% of enterprise AI pilots deliver zero measurable return (MIT, 2025). Microsoft 365 Copilot is already bundled into 450 million commercial seats, yet only 3.3% of users pay for it. The tool is right there, and people still don't use it. The problem was never access. It was value.
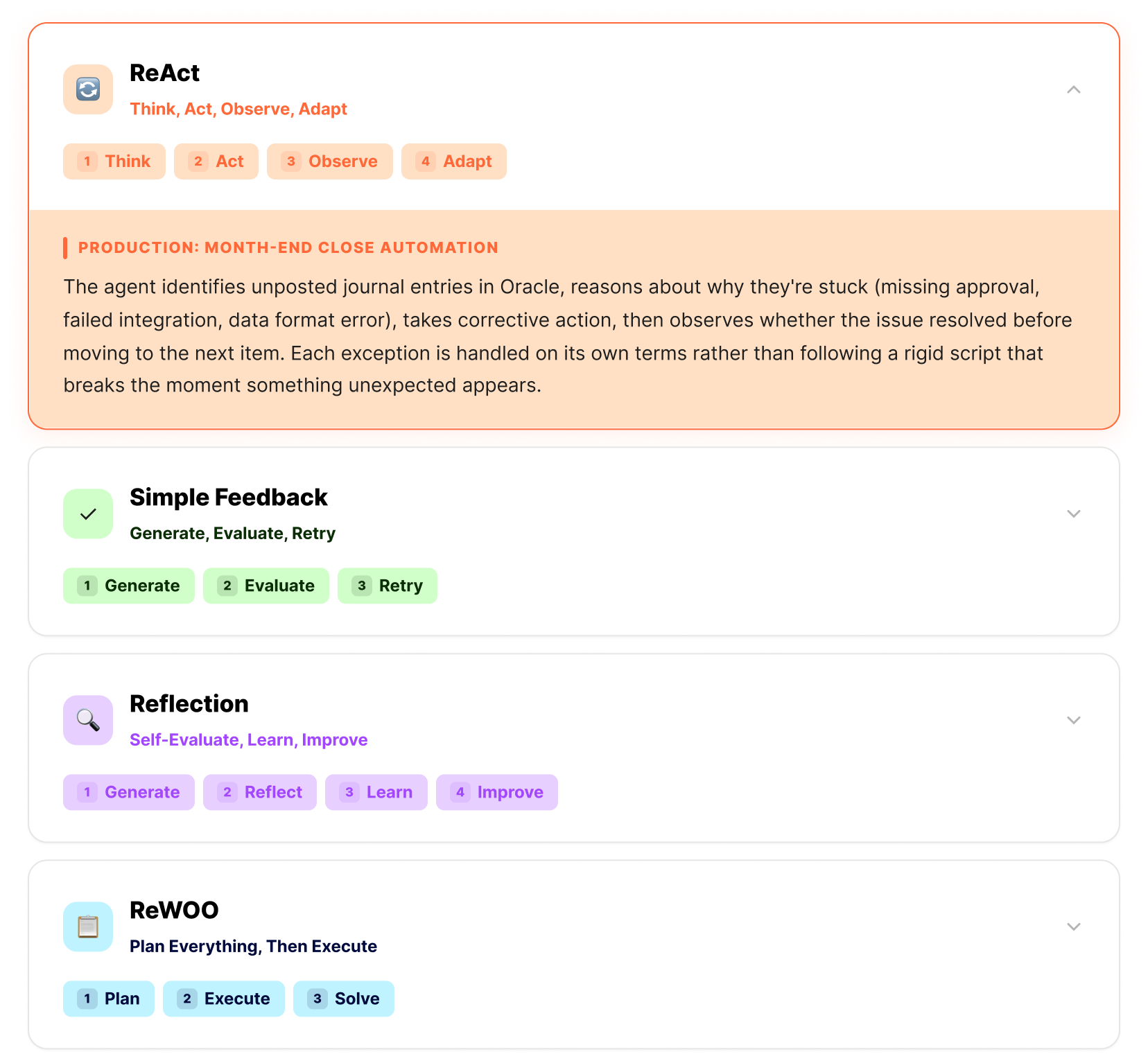
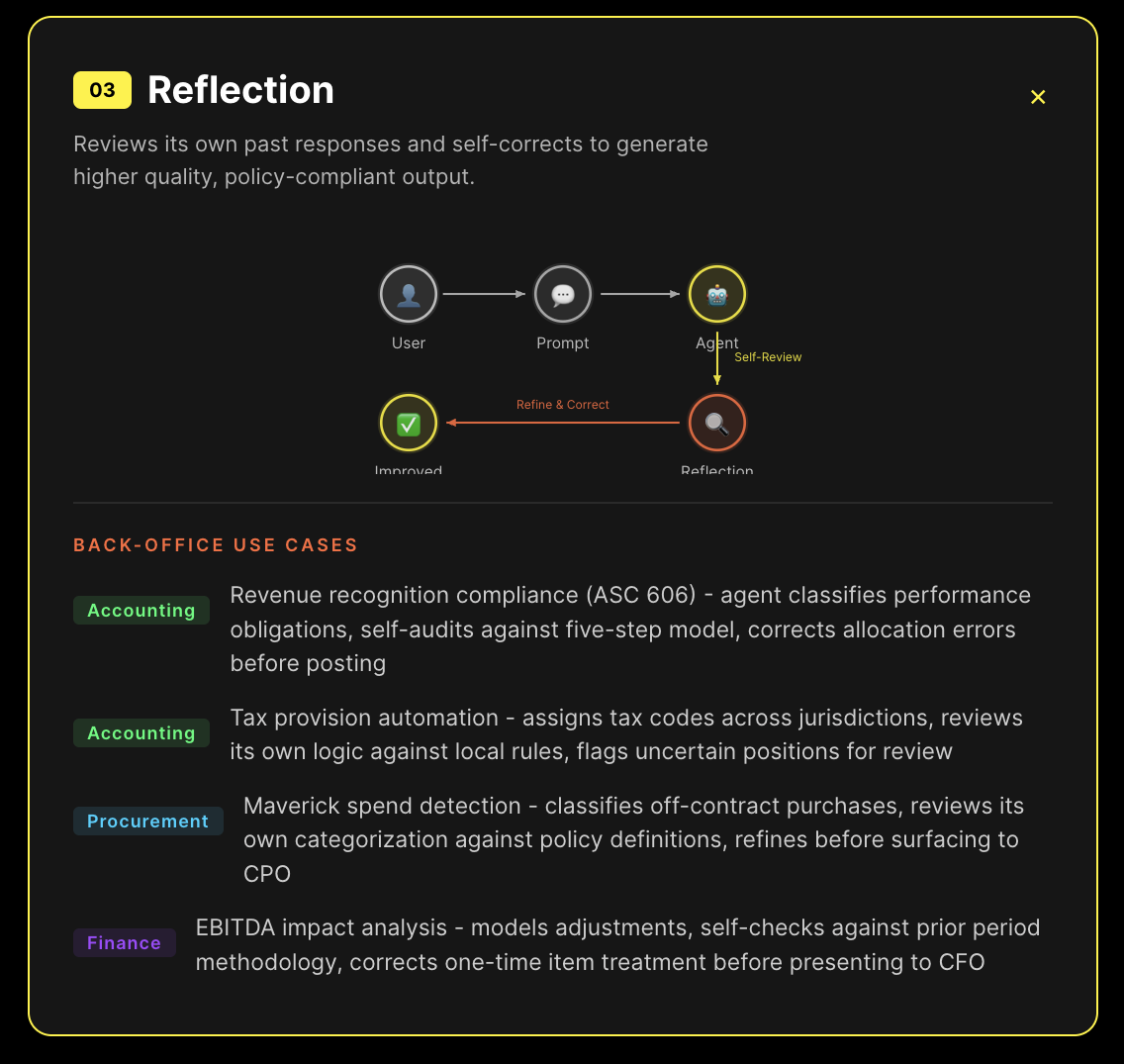
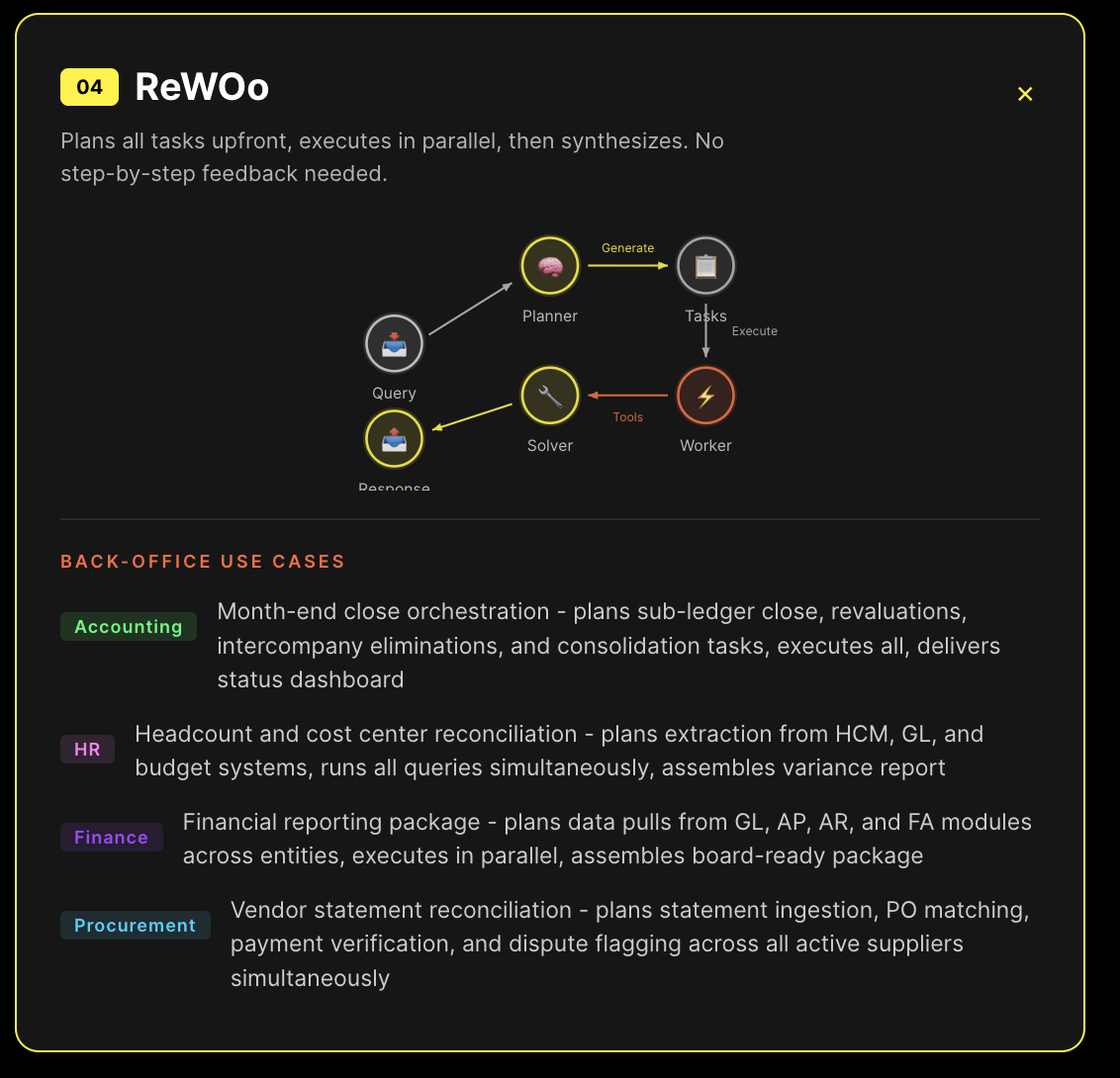
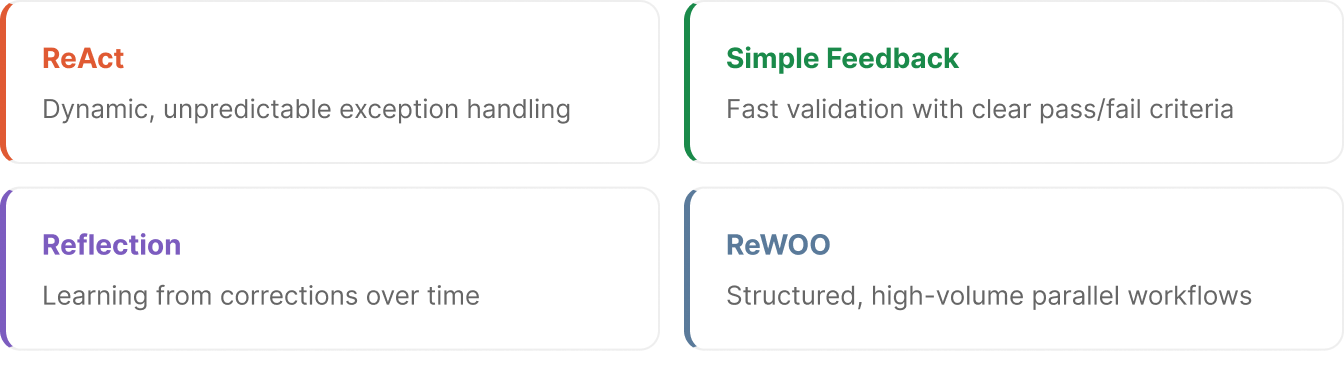
We build agentic AI for Oracle, Workday, and SAP back-office automation and any other system they interact with across your corporate ecosystem. Here are the four reasoning strategies we use in production and how each one maps to the work our agents actually do.

What follows is the reasoning architecture behind our production agents. Four strategies, each designed for a specific class of enterprise problem. The differences aren't academic - they determine whether your agent handles exceptions gracefully or falls apart the moment real data deviates from the demo script.