:quality(85)&w=1536&q=85)
:quality(85)&w=1536&q=85)
HERO scored 10/10 on the OWASP ASI 2026 standard, the emerging enterprise benchmark for AI agent security.
When we talk to enterprise teams about adopting AI, the conversation always follows the same arc. It starts with excitement: "Can your agent automate our month-end close?"and ends with a harder question:
"What stops it from doing something it shouldn't?"
 It's the right question. AI agents aren't chatbots. They don't just answer questions; they act. They query databases, submit journal entries, trigger business processes, and send Slack messages. An agent with the wrong guardrails isn't just unhelpful; it's a liability.
It's the right question. AI agents aren't chatbots. They don't just answer questions; they act. They query databases, submit journal entries, trigger business processes, and send Slack messages. An agent with the wrong guardrails isn't just unhelpful; it's a liability.
In enterprise systems, that liability is concrete: posting incorrect journal entries, triggering financial workflows, modifying employee records, or executing actions across systems of record. The risk isn't theoretical; it's operational.
That's why we put HERO through the most rigorous agentic security benchmark available today.
What Is the OWASP Agentic Top 10?
If you've worked in web security, you know OWASP. Their Top 10 for web applications has been the industry standard for over two decades; the checklist that every penetration test, compliance audit, and security review references.
In 2026, OWASP published a new list: the Top 10 for Agentic Applications. It's the first authoritative security framework built specifically for AI agents; systems that don't just generate text, but take autonomous action in the real world.
The distinction matters. Traditional AI safety focuses on what a model says; hallucinations, bias, toxicity. The Agentic Top 10 focuses on something much harder: what an AI agent does when you give it access to tools, data, and other agents.

We used Microsoft's open-source Agent Governance Toolkit (AGT) to verify HERO against all 10 controls.
AGT is notable because it doesn't rely on prompt-based safety, the approach where you tell the LLM "please don't do bad things" in the system prompt and hope for the best. Instead, it evaluates whether your system has deterministic, application-layer controls for each risk category: policy enforcement that works regardless of what the model tries to generate.
We ran AGT's strictest verification mode; which goes beyond checking installed components and validates runtime evidence: policy files, deny-by-default rules, tool registration, audit sinks, identity providers, and dependency manifests. This distinction matters: configuration-based checks can pass even when controls are not enforced at runtime. Evidence mode validates that these controls are active, enforced, and observable in a live execution context.
The result:
Agent Governance Toolkit; Verification PASSED ✅
OWASP ASI 2026 Coverage: 10/10 (100%)
Mode: evidence (strict)
✅ ASI-01: Prompt Injection
✅ ASI-02: Insecure Tool Use
✅ ASI-03: Excessive Agency
✅ ASI-04: Unauthorized Escalation
✅ ASI-05: Trust Boundary Violation
✅ ASI-06: Insufficient Logging
✅ ASI-07: Insecure Identity
✅ ASI-08: Policy Bypass
✅ ASI-09: Supply Chain Integrity
✅ ASI-10: Behavioral Anomaly
Runtime Evidence: 6/6 checks passed
✅ Policy files loaded
✅ Deny-by-default semantics detected
✅ 32 tools registered and governed
✅ Audit sink configured
✅ Identity provider enabled
✅ Package manifest verified
10/10 component controls. 6/6 runtime evidence checks. Zero failures.
Note on control naming: The Agent Governance Toolkit uses its own control taxonomy (e.g., Insufficient Logging, Insecure Identity, Policy Bypass), which does not map 1:1 to OWASP's ASI-01 through ASI-10 naming. For this analysis, we mapped each AGT control to its corresponding OWASP ASI risk category based on control intent and coverage area. The 10/10 result reflects full coverage across all OWASP ASI risk classes, even where naming differs.
Achieving full coverage is non-trivial; most agent architectures fail one or more categories due to gaps in tool isolation, identity enforcement, or policy control at runtime.
But numbers alone don't tell the full story. Here's the design philosophy behind each one.
How HERO Addresses Each Risk
ASI-01: Prompt Injection
An attacker hijacks the agent's goals through crafted inputs.
Most AI products use a single, powerful agent with broad access. If you can trick that agent through prompt injection, you can potentially access everything it can access.
HERO takes a different approach. User requests are routed through a structured disambiguation pipeline before any tool execution begins. Requests pass through typed UI forms rather than free-text interpretation to determine intent. Even if prompt injection succeeds at the routing layer, it lands in a specialized agent with strictly limited capabilities. There's no single agent with access to everything.
ASI-02: Insecure Tool Use
Authorized tools are abused in ways they weren't designed for.
Every HERO agent receives a curated, minimal tool bundle; never the full set. Our SQL agent can query data, but can't send messages. Our monitoring agent can create alert rules, but can't modify financial records. No agent has access to shell commands, file deletion, or raw network connections.
The attack surface of each agent is exactly the tools it's been given. No more.
ASI-03: Excessive Agency
The agent has more capability than it needs for its task.
We enforce least privilege by construction. Each agent is built with only the specific tools required for its domain. Data queries are scoped to relevant schemas; agents don't see the full database catalog. Iterative processes have hard-coded cycle limits. Output formats are enforced through typed schemas, not suggestions.
An agent can't exceed its defined capability because the capability boundary is set at build time, not at prompt time.
ASI-04: Unauthorized Escalation
A sub-agent acquires more power than its parent intended.
HERO uses a hierarchical agent architecture where capabilities narrow monotonically as you go deeper. Sub-agents always have strictly fewer tools and permissions than their parent orchestrator. A nested agent can't call a tool that wasn't explicitly granted to it, regardless of what the underlying model generates.
When a sub-agent completes its work, it escalates results upward; it can never grant itself new capabilities or reach sideways to another agent's tools.
ASI-05: Trust Boundary Violation
The agent bypasses isolation to access forbidden systems.
HERO agents never connect directly to infrastructure. Every operation, report execution, data query, journal import, and process submission is proxied through a backend API layer with its own authentication, authorization, and audit controls. Database access is read-only at the API level. There are no shell-access tools, no raw subprocess execution, and no direct network connectivity available to any agent.
ASI-06: Memory & Context Poisoning
Long-running context is contaminated with malicious instructions.
Agent state in HERO is session-scoped; it doesn't persist across conversations. There's no long-running memory store that could accumulate poisoned context over time. Between agents, data flows through typed artifacts and structured state keys, not free-text messages that could be manipulated.
Stale context is actively pruned before it reaches the model, and every agent action is traced through our observability platform, Langfuse, creating a tamper-evident audit trail.
ASI-07: Insecure Inter-Agent Communication
Agents collaborate without authentication or validation.
HERO agents don't communicate over the network. They operate within a single runtime, delegating work through typed interfaces with structured parameters. Every user session is authenticated via JWT through an edge proxy, and the authenticated identity is available to every agent in the chain.
There are no HTTP calls between agents, no message queues, and no shared databases that could be intercepted or spoofed.
ASI-08: Cascading Failures
One failure triggers compound failures across the system.
In HERO, iterative processes use hard circuit breakers: if an agent loop can't converge on a correct result within a fixed number of cycles, it terminates and escalates. Errors are classified by type with deterministic handling rules: some are retried, some are surfaced to the user, and some trigger an escalation to human support.
Critically, sub-agents are isolated from each other. A failure in one domain agent doesn't affect any other agent; they share no state, tools, or failure modes.
ASI-09: Human-Agent Trust Exploitation
Users approve dangerous actions they don't fully understand.
For high-impact actions, such as creating journal entries, executing month-end processes, and modifying monitoring rules, HERO uses interactive confirmation workflows with structured forms. You can't approve a destructive operation through casual conversation.
Financial submissions go through multi-phase verification: the system confirms both that the action succeeded and that no errors were silently rejected. Monitoring rules are validated against live data before creation; they can't be built from hallucinated conditions.
ASI-10: Rogue Agents
An agent operates outside its defined scope.
Agent definitions in HERO are immutable at runtime. Tools, prompts, and sub-agent relationships are set in code, not in a database that could be modified during execution. An agent can't rewrite its own tool list or alter another agent's permissions.
We also have a dedicated monitoring subsystem that specifically watches for anomalies in operational data; threshold violations, duplicate records, compliance deviations, providing a continuous behavioral check on the system's outputs.
Why This Matters
Most AI products today rely on prompt-based safety; instructions in the system prompt that tell the model to behave. The problem is well-documented:
Red-team testing consistently shows that prompt-based safety controls can be bypassed under adversarial conditions, often at non-trivial rates depending on the attack surface and model configuration.
HERO's approach is fundamentally different. Security is structural, not instructional. The model can generate anything, but it can only execute what the system allows.
Tool access is defined at build time, not requested at prompt time
Iteration limits are enforced by the framework; not suggested to the model
Agent permissions narrow monotonically down the hierarchy, not by recommendation
Destructive actions require explicit human confirmation through typed forms; not conversational approval
When the Agent Governance Toolkit verifies these controls, it's confirming that the safety layer operates independently of the model. The LLM can generate whatever it wants; if the tool isn't in its bundle, the call doesn't execute. If the iteration cap is reached, the loop terminates. If the policy says deny, the action is blocked.
That's the difference between hoping your agent behaves and knowing it can't misbehave.
For Security Teams
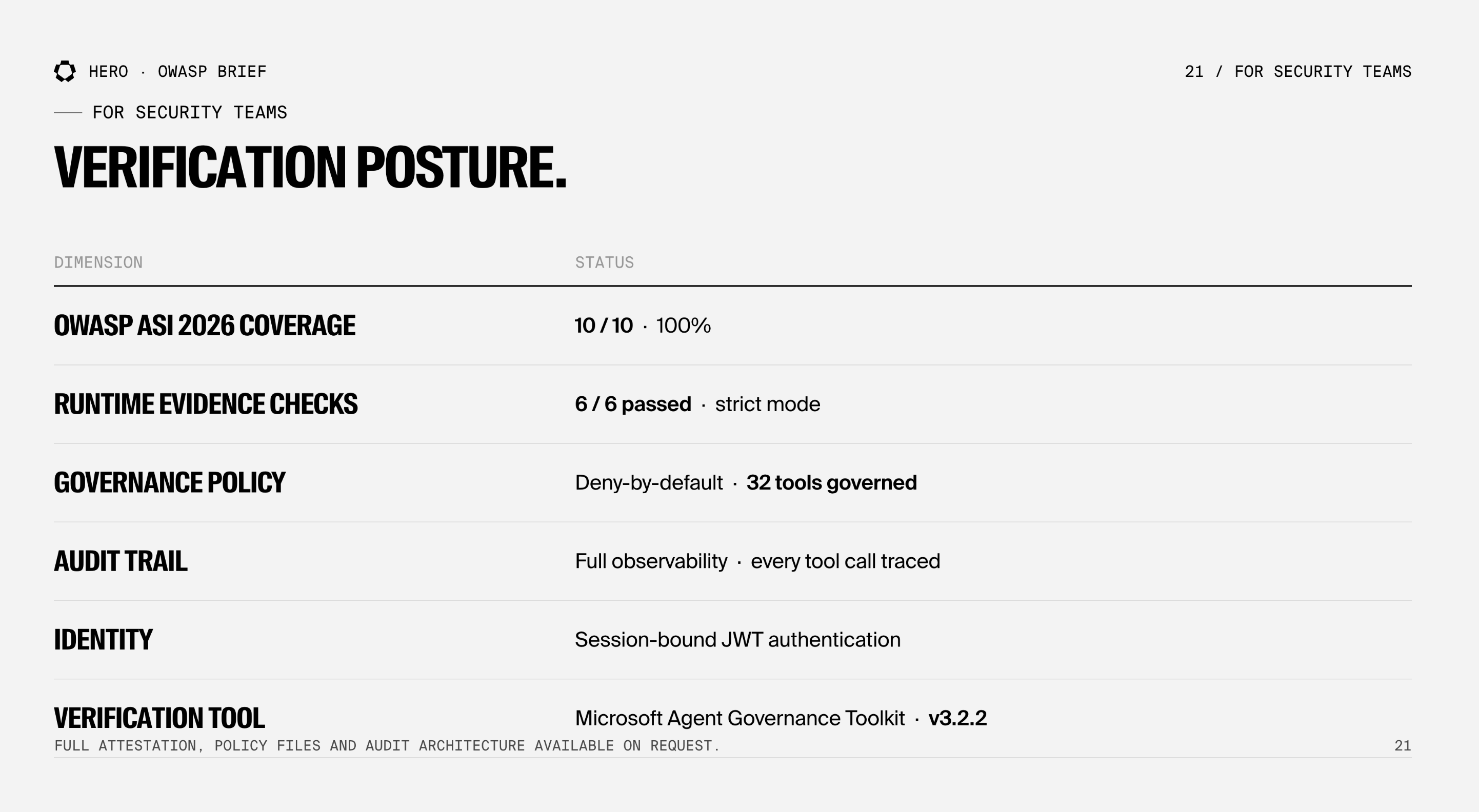
We're happy to walk through the full attestation, policy files, and audit architecture in a security review. Contact us to schedule a session.
What's Next
Passing the OWASP ASI 2026 standard with full evidence is our baseline, not the finish line. We're continuing to invest in:
Runtime policy enforcement; Integrating governance evaluation into every tool call in production, not just verification
CI/CD compliance gates; Automated regression testing against the OWASP standard on every code change
Live evidence generation; Dynamically producing compliance manifests from agent definitions so they're always in sync
SOC 2 readiness; Structured audit exports for enterprise compliance reviews.

The era of "trust the prompt" is over. Enterprise AI agents need deterministic, verifiable security controls, and that's exactly what we've built.